After spending a lot of time with language models, I have come to the conclusion that tokenization in general is insane and it is a miracle that language models learn anything at all. To drill down into one specific example of silliness which has been bothering me recently, let’s look at how the GPT2 tokenizer (which is also used for GPT3 as far as I know) tokenizes integers. The tokenization of integers is the most basic element of learning and representing mathematical facts and ultimately all of GPTs mathematical capabilities have to be built from this foundation.
The major issue is that the tokenizer does not represent numbers in decimal or indeed in any coherent format. The ideal decimal system would assign unique tokens to the integers 0 to 9 and then represent larger integers as combinations of these unique tokens. The decimal system (and indeed representing integers to any coherent base) allows straightforward algorithms for addition, subtraction, multiplication etc to be defined.
However, the GPT2 tokenizer does not do this and indeed does not represent integers in any coherent base. The decimal numbers 0-9 are hardcoded in its token set along with the rest of the ascii characters, but beyond that the BPE algorithm also tokenizes other common number chunks into unique tokens and not always in a coherent way. Instead a huge chunk of integers are assigned their own unique token. This is shown below
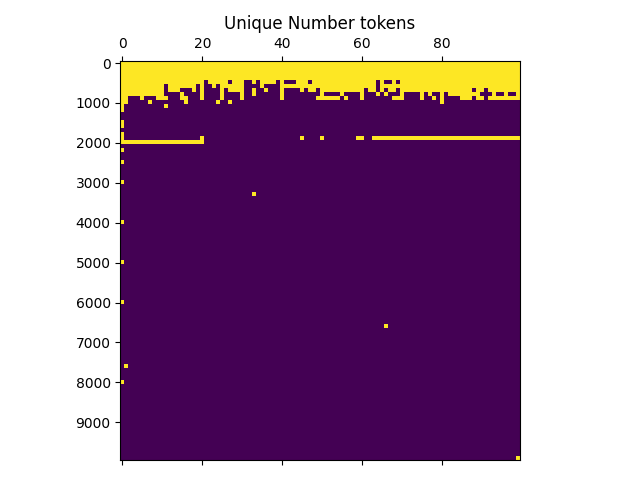
Each row here represents 100 integers so that the whole matrix represents the first 10k integers from 1 - 10000. If a square is colored yellow it means a unique token is assigned to that integer and if it is blue then the integer is coded by a composite set of tokens. We observe that every single integer up until 521 is assigned its own unique token identifier, as are many numbers after that. In the first 10000 integers there are 916 unique tokens (so almost 1/10th) of the tokens are unique and the number tokens take up about 1 50th of the total tokenizer space (GPT2s tokenizer is approximately 50k tokens). This means that any calculation or mathematical problem which involves these integers in any way must be special-cased somehow and operate off of pure memorization. For instance, the model cannot use a normal addition algorithm when given a problem like 54 + 72 = 126 since every single one of these tokens are unique. Instead it must memorize an extremely large number of problems and their answers. Essentially almost all two and most 3 digit addition and subtraction problems must be solved with memorization instead of a coherent and generalizable algorithm.
If we examine the plot more closely we see that even outside the first 1000 digits, there are still significant patches of unique digits. Many recognizable numbers which occur commonly in the training set for whatever reason are assigned a unique digit, requiring learnt special case machinery for any calculation involving these. An interesting feature is also the band of integers assigned unique tokens in the 1900-2000 region. These represent common dates – i.e. from 1930-2020 are all assigned unique tokens because these dates occur most frequently in the training set (interestingly unique tokens are assigned up to the year 2020 and then abruptly stop, allowing you to date the tokenizer creation to 2019-2020).
The silliness with tokenization also extends beyond just a lot of unique tokens and into how the non-unique integers are tokenized. The model definitely does not resort to a coherent decimal system for these. Instead, it breaks the integers up into chunks which are then tokenized in an ad-hoc way. The way integers are broken up into chunks can vary between different numbers even right next to each other. For instance, the number: 2249 is tokenized as ‘2’, and ‘249’ (1-3). The number 2250 is tokenized as ‘22’ and ‘50’ (2-2) and the number ‘2251’ is tokenized as ‘225’ and ‘1’ (3-1).
If we repeat our analysis but color in the different categories for how 4 digit numbers are tokenized – i.e. as unique, 1-3 length tokens, 2-2 tokens or 3-1 tokens, we get the following result.
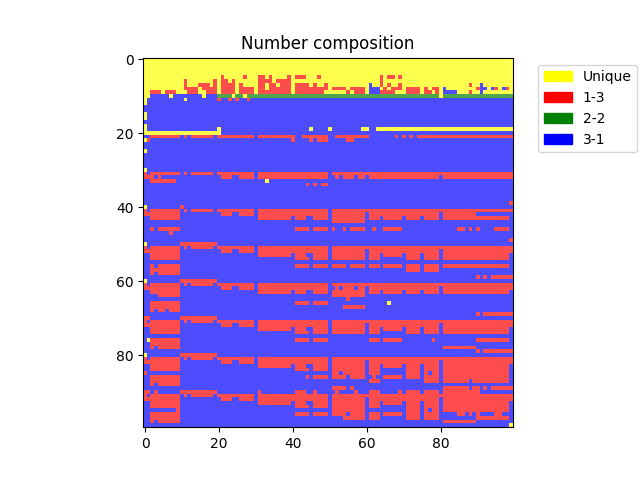
There is clearly a non-random distribution of different encoding strategies, where for each row of 1000 there is a somewhat repeated pattern of encoding. But if you look closely it is also fairly inconsistent in its exact details. Ultimately, what this means is that to execute even simple numerical algorithms like multi-digit addition, the model has to learn a series of special cases depending on the exact details of the tokenization and, from looking the tokenization of larger numbers it looks like this problem never really goes away and there is always inconsistent chunking of large numbers into tokens and the occasional unique token to contend with. Life is tough as a language model.